分享嘉宾:Bonnie
今天我们讨论一下样本不平衡问题以及介绍一些相关的解决方案。
首先看下工程化建模流程从数据出发的6个维度,包括:
1、业务理解:从实际业务出发,明确业务需求
2、数据理解:从实际数据出发,明确数据特点,如数据更新周期等
3、数据预处理:对数据进行清洗、处理和特征工程,并对样本进行筛选
4、建模:引入相关模型方法,完成模型需求
5、模型整体评估:进行模型效果,确保模型效果达到实际需求
6、数据表达:整个数据应用、建模过程的标书
本次分享主要针对建模流程中的数据预处理过程,进行样本筛选,确定样本分布满足建模需求或者使模型样本能够准确表达业务需求。
一、什么是样本不均衡?
所谓的不平衡指的是不同类别的样本量差异非常大,或者少数样本代表了业务的关键数据(少量样本更重要),需要对少量样本的模式有很好的学习。样本类别分布不平衡主要出现在分类相关的建模问题上。
样本类别分布不均衡从数据规模上可以分为大数据分布不均衡和小数据分布不均衡两种:
(1)大数据分布不均衡——整体数据规模较大,某类别样本占比较
小。例如拥有1000万条记录的数据集中,其中占比5万条的少数分类样本便于属于这种情况。
(2)小数据分布不均衡——整体数据规模小,则某类别样本的数量也少,这种情况下,由于少量样本数太少,很难提取特征进行有/无监督算法学习,此时属于严重的小数据样本分布不均衡。例如拥有100个样本,20个A类样本,80个B类样本。
二、在实际工程中,样本不平衡的场景有哪些?
(1)异常检测场景——比如恶意刷单、黄牛订单、信用卡欺诈、电力窃电、设备故障等,这些数据样本所占的比例通常是整体样本中很少的一部分,以信用卡欺诈为例,刷实体信用卡的欺诈比例一般都在0.1%以内。
(2)客户流失场景——大型企业的流失客户相对于整体客户通常是少量的,尤其对于具有垄断地位的行业巨擘,例如电信、石油、网络运营商等更是如此。
(3)罕见事件的分析——罕见事件分析与异常事件的区别在于异常检测通常是预先定义好的规则和逻辑,并且大多数异常事件都对会企业运营造成负面影响,因此针对异常事件的检测和预防非常重要;但罕见事件则无法预判,并且也没有明显的积极和消极影响倾向。异常事件的检测往往采用异常检测的方法,后续会有相关介绍。
(4)发生频率低的事件——这种事件是预期或计划性事件,但是发生频率非常低。例如每年1次的双11盛会一般都会产生较高的销售额,但放到全年来看这一天的销售额占比很可能只有1%不到,尤其对于很少参与活动的公司而言,这种情况更加明显。这种属于典型的低频事件。
三、工程过程中,应对样本不均衡问题应从哪些方面入手?
(1)欠采样:在少量样本数量不影响模型训练的情况下,可以通过对多数样本欠采样,实现少数样本和多数样本的均衡。
(2)过采样:在少量样本数量不支撑模型训练的情况下,可以通过对少量样本过采样,实现少数样本和多数样本的均衡。
(3)模型算法:通过引入有倚重的模型算法,针对少量样本着重拟合,以提升对少量样本特征的学习。
接下来我们分别介绍一下每个方向有哪些常见算法。
四、样本均衡处理
4.1 样本均衡---欠采样
欠抽样(也叫下采样、under-sampling,US)方法通过减少分类中多数类样本的样本数量来实现样本均衡。通过欠采样,在保留少量样本的同时,会丢失多数类样本中的一些信息。经过欠采样,样本总量在减少。
那么欠采样有哪些方法呢?
4.1.1 随机删除
随机删除,即随机的删除一些多量样本,使少量样本和多量样本数量达到均衡。
随机删除主要做法如下:
分别确定样本集中多量样本数和少量样本数;
确定采样样本集中多量样本和少量样本比值;
以少量样本为基准,确定多量样本采样总数;
以为限,对多量样本进行随机抽样。
该算法中,可以以样本序号为种子,利用python自带的random.sample()函数进行采样,如
4.1.2 原型生成(Prototype generation)
原型生成方法将会根据原始数据集重新生成一个数据集,新生成的数据集的样本量小于原始数据集的样本量,且新生成的数据集的样本不在原始数据集中(不是原始数据集的子集)。也就是说,原型生成的方法得到的数据集是生成得到的,而不是从原始样本中进行选择。最常见的原型生成算法是通过聚类来实现,例如用k-means算法得到聚类中心之后,根据聚类中心来生成新的样本。
具体做法如下:
以少量样本总数出发,确定均衡后多量样本总数;
从多量样本出发,利用k-means算法随机的计算K个多量样本的中心;
认为k-means的中心点可以代表该样本簇的特性,以该中心点代表该样本簇;
重复2/3两步,生成新的多量样本集合 并且
基本用法python代码如下:
from imblearn.under_sampling import ClusterCentroids
cc = ClusterCentroids(random_state=0)
X_resampled, y_resampled = cc.fit_resample(X,y)
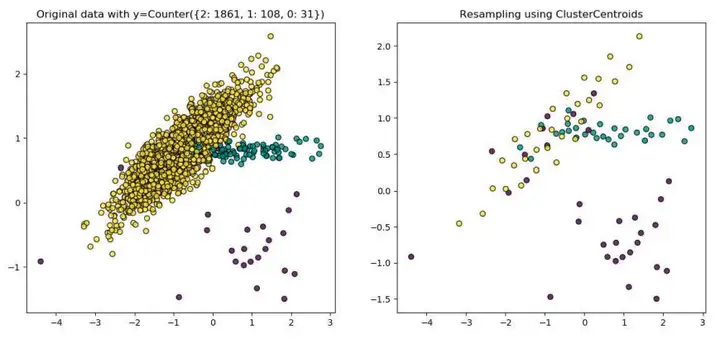
下图所示为三类2000个样本点的集合,每个样本维度为2---即样本共有2个特征,其中,。利用PG算法完成样本均衡后,样本整体分布没有变化。
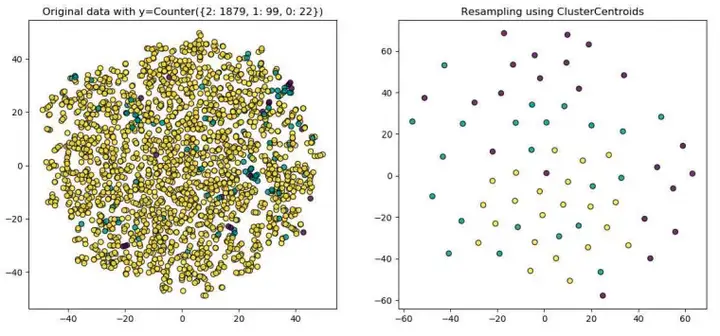
下图所示为三类2000个样本点的集合,每个样本维度为8---即样本共8个特征,其中,。由于是高维数据,散点图所示为经过t-SNE降维后的结果。可以看出在高维情况下,均衡后样本间的关系发生了变化——即在高维情况下,K-means的类中心不能很好地代表样本簇的特点。
4.1.3 原型选择(Prototype selection)
与原型生成不同,原型选择是直接从原始数据集中进行抽取。即新生成的数据集样本量小于原始数据集的样本量,新生成的数据集的样本。抽取的方法可以分为两类:
(1)Controlled under-sampling techniques(可控的下采样技术)——即对多量样本进行抽选,以达到需要的均衡样本集。具体的方法可以是随机抽选、基于bootstrap的抽选和启发式规则的抽样。
参考代码:
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_resampled, y_resampled = rus.fit_resample(X, y)
from imblearn.under_sampling import NearMiss
nm1 = NearMiss(version=1)
X_resampled_num1, y_resampled = nm1.fit_resample(X, y)
(2) Cleaning under-sampling techniques(基于数据清洗方法的下采样技术)——该类算法主要包括三个细分小类:a)基于距离的Tomek’s link判别方法;b)基于nearest-neighbors的算法;c)基于1-NN分类器的构建方法上述方法主要区别在于筛选多量样本的算法不同,但是都用的是原生样本,即生成的新样本
4.1.4 算法集成
算法集成( Ensemble ),可以理解为对一个不均衡的数据集能够通过多个均衡的子集来实现均衡的过程 。主要借助Boost的思路,实现多个子集合的集成。
BOOST算法是一种通用的学习算法,这一算法可以提升任意给定的学习算法的性能。其思想源于1984年Valiant提出的”可能近似正确”PAC(Probably Approximately Correct)学习模型,在PAC模型中定义了两个概念-强学习算法和弱学习算法。其概念是: 如果一个学习算法通过学习一组样本,识别率很高,则称其为强学习算法。如果识别率仅比随机猜测略高,其猜测准确率大于50,则称其为弱学习算法
基于欠采样的集成方法步骤如下:
以均衡样本作为一句,对多量样本抽样,组成具有K个样本的训练集;
对该训练集学习,得到第一个若分类器;
引入新的数据,并和分错的数据进行组合,构建一个新的K个样本的训练集,通过学习得到第二个弱分类器;
继续第三步,构建新的样本集和弱分类器。训练的次数n是一个超参数;
经过n次训练后,把所有的分类器进行集成,最终得到一个强分类器,即某个样本的分类要通过的多数表决来确定。
上述方法为基本的基于欠采样的集成方法,对于弱集成器的个数和最终的投票算法,可根据实际需求进行改进,比如以各个若分类器的准确度为权重进行加权等。
imblearn.ensemble模块通过对原始的数据集进行随机下采样实现对数据集进行集成.
from imblearn.ensemble import EasyEnsemble
ee = EasyEnsemble(random_state=0, n_subsets=10)
X_resampled, y_resampled = ee.fit_sample(X, y)
针对算法集成,C.Seiffert (2010)提出了基于AdaBoost.M2算法——RUSBoost。算法流程如下
4.2 样本均衡---过采样
过抽样(也叫上采样、over-sampling)方法通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录,这种方法的缺点是如果样本特征少,可能导致过拟合的问题。
经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,对应的算法会在后面介绍。
4.2.1 过采样——随机复制
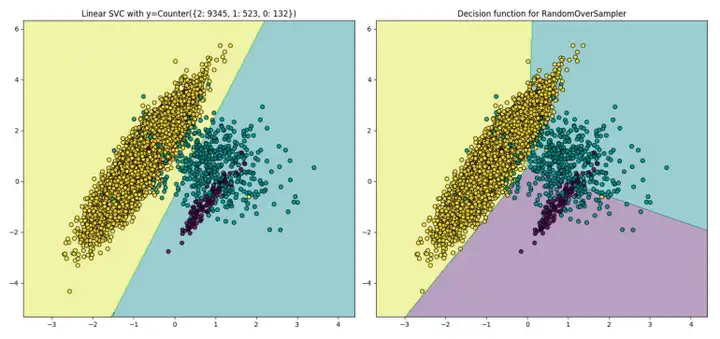
随机复制即对少量样本进行复制后达到样本均衡的效果以提升模型效果。如下图所示,在进行复制前,Linear SVC只找到一个超平面——即认为样本集中仅两类样本。随机复制后, Linear SVC找到了另外两个超平面。
4.2.2 过采样——样本构建
在随机过采样的基础上,通过样本构造一方面降低了直接复制样本带来的过拟合风险,另一方面实现了样本均衡。比较典型的样本构造方法有SMOTE(Synthetic minority over-sampling technique)及其衍生算法。
(1) SMOTE算法通过从少量样本集合中筛选的样本和及对应的随机数0 < < 1,通过两个样本间的关系来构建新的样本。
由于SMOTE算法构建样本时,是随机的进行样本点的组合和 参数设置,因此会有以下2个问题:
1)在进行少量样本构造时,未考虑样本分布情况,对于少量样本比较稀疏的区域,采用与少量样本比较密集的区域相同的概率进行构建,会使构建的样本可能更接近于边界;只是简单的在同类近邻之间插值,并没有考虑少数类样本周围多数类样本的分布情况。
2)当样本维度过高时,样本在空间上的分布会稀疏,由此可能使构建的样本无法代表少量样本的特征。
(2) 自适应合成抽样(ASASYN,adaptive synthetic sampling)算法是在SMTOE基础上提出的,其最大的特点是采用某种机制自动决定每个少数类样本需要产生多少合成样本,而不是像SMOTE那样对每个少数类样本合成同数量的样本。算法流程如下:
参考代码:
from imblearn.over_sampling import SMOTE, ADASYN oversample = ADASYN(random_state=40) X = train_data_c[features] Y = train_data_c[‘label’] X, Y = oversample.fit_resample(X, Y)
(3)一系列衍生方法:SMOTEBoost、Borderline-SMOTE、Kmeans-SMOTE等。
1)SMOTEBoost把SMOTE算法和Boost算法结合,在每一轮分类学习过程中增加对少数类的样本的权重,使得基学习器(base learner) 能够更好地关注到少数类样本。
2)Borderline-SMOTE在构造样本时考虑少量样本周围的样本分布,选择少量样本集合(DANGER集合)——其邻居节点既有多量样本也有少量样本,且多量样本数不大于少量样本的点来构造新样本。
3)Kmeans-SMOTE包括聚类、过滤和过采样三步。利用Kmeans算法完成聚类后,进行样本簇过滤,在每个样本簇内利用SMOTE算法构建新样本
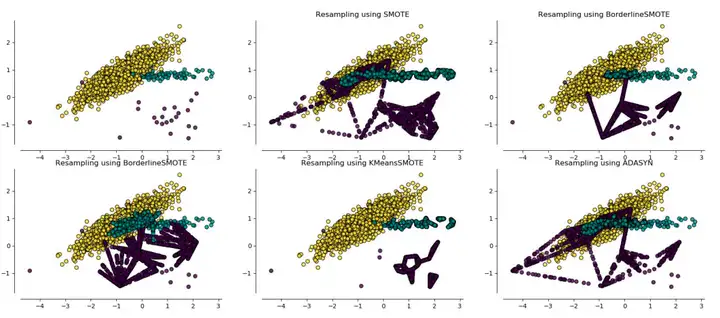
通过比较不同算法得到的样本构造,可得以下结论:
1).利用样本构建的方法,可以得到新的少量样本;
2).利用不同算法构建的新样本在数量和分布上不同,其中利用SMOTE算法构建的新样本,由于没有考虑原始样本分布情况,构建的新样本会受到“噪声”点的影响。同样ASASYN算法只考虑了分布密度而未考虑样本分布,构建的新样本也会受到“噪声”点的影响。Borderline-SMOTE算法由于考虑了样本的分布,构建的新样本能够比较好的避免“噪声”点的影响。Kmeans-SMOTE算法由于要去寻找簇后再构建新样本,可构建的新样本数量受限。
注:“噪声”点对应类别上属于少量样本,但是分布上比较靠近边界或者与多量样本混为一起。
4.3 样本均衡---模型算法
上述的过采样和欠采样都是从样本的层面去克服样本的不平衡,从算法层面来说,也可以克服样本不平衡。在现实任务中常会遇到这样的情况:不同类型的错误所造成的后果不同。
例如:在医疗诊断中,错误地把患者诊断为健康人与错误地把健康人诊断为患者,看起来都是犯了“一次错误”,但是后者的影响是增加了进一步检查的麻烦,前者的后果却可能是丧失了拯救生命的最佳时机;
再如,门禁系统错误地把可通行人员拦在门外,将使得用户体验不佳,但错误地把陌生人放进门内,则会造成严重的安全事故;
在信用卡盗用检查中,将正常使用误认为是盗用,可能会使用户体验不佳,但是将盗用误认为是正常使用,会使用户承受巨大的损失。
为了权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”(unequal cost)
COST SENSITIVE算法
代价敏感学习方法的核心要素是代价矩阵,如表1所示。其中表示将第i 类样本预测为第j 类样本的代价。一般来说,。若将第0类判别为第1类所造成的损失更大,则;损失程度相差越大,与的值差别越大。当与相等时为代价不敏感的学习问题。
表 1
基于代价敏感的方法,这类分析可以大致分为三大类:
1.从学习模型出发,对某一具体学习方法的改造,使之能适应不平衡数据下的学习,研究者们针对不同的学习模型如感知机、支持向量机、决策树、神经网络等分别提出了其代价敏感的版本。以代价敏感的决策树为例,可以从三个方面对其进行改造以适应不平衡数据的学习,这三个方面分别是决策阈值的选择方面、分裂标准的选择方面、剪枝方面,这三个方面都可以将代价矩阵引入。
2.从贝叶斯风险理论出发,把代价敏感学习看成是分类结果的一种后处理,按照传统方法学习到一个模型,以实现损失最小为目标对结果进行调整。此方法的优点在于它可以不依赖所用的具体分类器,但是缺点也很明显,它要求分类器输出值为概率。
3.从预处理的角度出发,将代价用于权重调整,使得分类器满足代价敏感的特性。
第一大类主要是:
1)决策树的代价敏感的剪枝方法,在代价敏感的条件下如何对决策树进行剪枝使得损失达到最小,研究表明基于拉普拉斯方法的剪枝方法能够取得最好的效果。代价敏感学习的决策树的节点分裂方法。
2)Boosting:代价敏感的Boosting 算法Ada-Cost。
3)神经网络:基于Perceptron 分类算法的代价敏感的学习方法,在文章中作者对不可分的类提出了代价敏感的参数更新规则。例如,新的神经网络后向传播算法,使之能够满足代价敏感学习的要求。
4)从结构风险最小的角度来看代价敏感问题,提出了代价敏感的支持向量机分类算法。
大家只需要记住,第一大类方法就是在建立模型的时候,我告诉模型,你需要去关注少量样本的特征。
Github: https:// github.com/krisqwl/cost -sensitive-learning
该类以adacost算法为例。AdaCost算法通过反复迭代,每一轮迭代学习到一个分类器,并根据当前分类器的表现更新样本的权重,如图中红框所示,其更新策略为正确分类样本权重降低,错误分类样本权重增大,最终的模型是多次迭代模型的一个加权线性组合。分类越准确的分类器将会获得越大的权重。
第二大类主要是:
1)基于对分类结果的后处理,即按照传统的学习方法学习一个分类模型,然后对其分类结果按照贝叶斯风险理论对结果进行调整,以达到最小的损失。
2)和第一类代价敏感学习方法相比,这种方法的优点在于其不依赖于所使用的具体的分类器。3)一种叫做MetaCost 的过程,它把底层的分类器看成一个黑箱子,不对分类器做任何的假设和改变,MetaCost可以应用到任何个数的基分类器和任何形式的代价矩阵上。
该类以MetaCost算法为例。MetaCost算法流程:
1) 在训练集中多次采样,生成多个模型。
2) 根据多个模型,得到训练集中每条记录属于每个类别的概率。
3) 计算训练集中每条记录的属于每个类的代价,根据最小代价,修改类标签。4) 训练修改过的数据集,得到新的模型
第三大类主要是:
1) 基于传统的学习模型,通过改变原始训练数据的分布来训练得到代价敏感的模型。
2) 如层次化模型(Stratification),把分布不均匀的训练数据调整为正负例均匀分布的数据。
3) 基于cost-proportionate 的思想,对训练数据调节权值,在实际应用中,其类似于Boosting 算法,可以通过为分类模型调节权值来进行实现,又可以通过采样(subsampling)来实现。4) 对多类分类问题中如何实现代价敏感的学习进行了探讨,提出了一种新的迭代学习方法。
该类以Dice Loss为例。 使用dice loss替代标准的交叉熵作为数据不平衡问题下的目标函数。通过平衡FP和FN在目标函数中的重要性,做到对样本不平衡问题的针对。
在实际建模工作中,除了样本均衡外,还有数据质量评估、样本筛选、指标构建、模型方法选择、模型调优、模型监控等一系列的工作。
本次分享仅从样本筛选中的一个点出发,介绍了在建模过程中可能遇到的样本问题。实际上在整个建模过程中各个阶段可能遇到的问题,需要大家不断尝试、不断积累经验。加油!
「静月影:@Bonnie ,老师对于噪声的处理,有什么案列和处理函数吗?」
「瑞子:@Bonnie 您好老师,中餐菜品图像识别,有没有推荐的资料、算法,作参考」
觉得不错的话,记得帮我 @小象 点个赞哟,祝大家都能学有所获!